AI / ML Experiment Report
Deep Learning Model Experiments
University deep learning work comparing image-classification CNNs on CIFAR-10 and recurrent sentiment models on IMDb reviews.
Overview
Two experiments, one goal: understand model behaviour.
The folder contains two university deep learning assignments. The first used PyTorch to compare softmax regression and CNN models on CIFAR-10 image classification. The second compared Vanilla RNN, LSTM, and Bidirectional LSTM models for IMDb sentiment analysis.
My work was focused on building the training/evaluation code, running controlled comparisons, reading the training curves, and explaining what the results said about model complexity, generalisation, and training cost.
I am not publishing the full reports or notebooks directly. This page summarises the work and includes only selected chart images that are safe to show publicly.
Tools and concepts
- Python and PyTorch for model building, training, and evaluation.
- Torchvision transforms and DataLoader workflows for CIFAR-10.
- Softmax regression, CNN depth experiments, dropout, weight decay, learning-rate analysis, and mini-batch-size comparison.
- IMDb text preprocessing with tokenisation, vocabulary limits, padding, packed sequences, and recurrent models.
- Vanilla RNN, LSTM, and Bidirectional LSTM comparison using accuracy, parameter count, and epoch time.
- Experiment tracking through plotted loss/accuracy curves and summary tables rather than relying on one final number.
Selected evidence
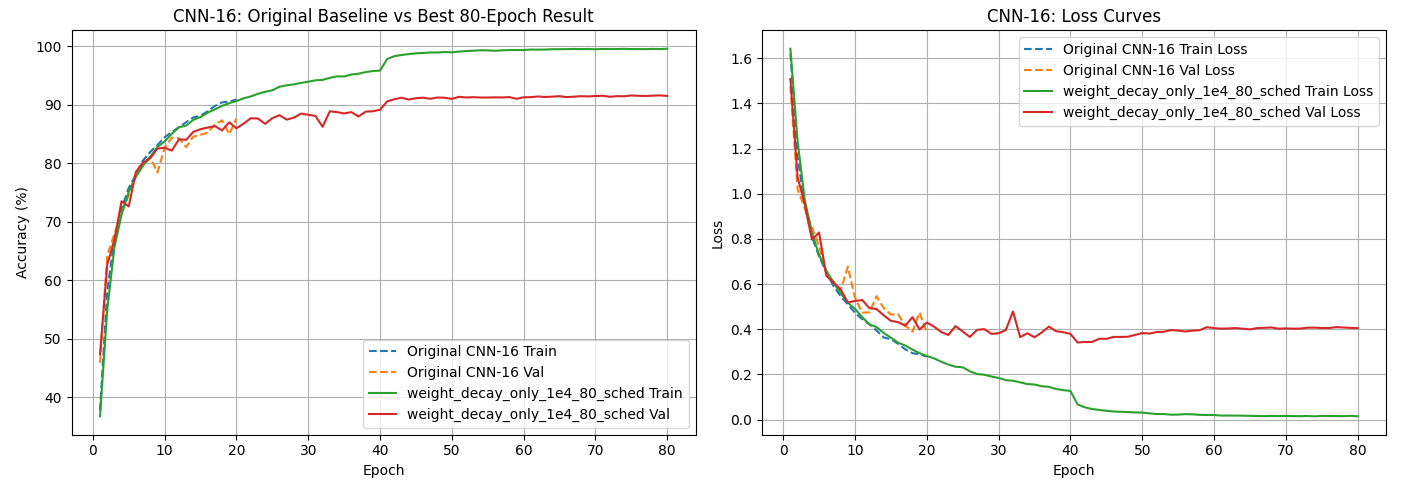
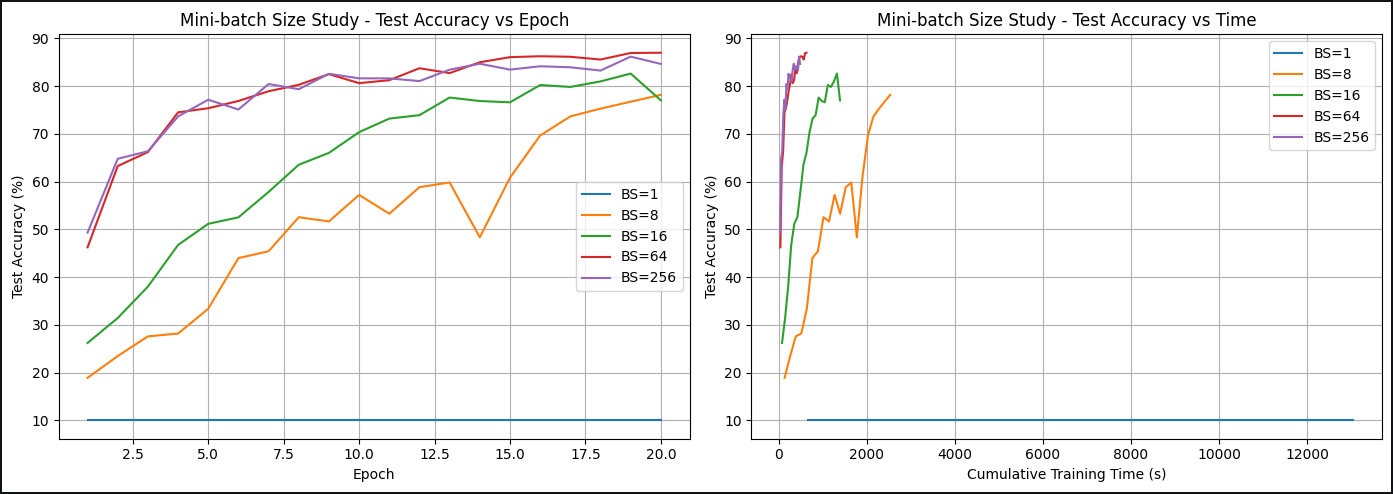
What I did
I built training and evaluation pipelines, defined model classes, compared model variants, plotted training curves, and wrote up the results in terms of accuracy, generalisation, optimisation behaviour, and training cost.
For the CIFAR-10 work, I started with softmax regression as a simple baseline, then compared CNN depth and regularisation choices. The stronger CNN experiments showed me how much architecture, training length, and weight decay can change results. The best improved CNN experiment in my notebook used weight decay with a longer training schedule and reached 91.35% test accuracy at the best validation point.
For the sentiment work, I trained recurrent models and compared how well each architecture handled review sequences. That made the differences between a basic RNN, an LSTM, and a bidirectional LSTM feel concrete rather than theoretical.
Key implementation and analysis details
- Implemented reusable PyTorch training and evaluation functions for image classification experiments.
- Compared CNN depth and regularisation choices to understand how architecture and training settings changed results.
- Used a softmax regression baseline to show why a linear model was limited on image data before moving to CNNs.
- Tested learning-rate and mini-batch-size settings to see how optimisation choices affected accuracy and training time.
- Used packed sequences in the sentiment project so recurrent models could ignore padding tokens.
- Compared recurrent model tradeoffs: Vanilla RNN was fastest but weakest, LSTM improved accuracy, and Bidirectional LSTM reached the strongest result.
- Reported final sentiment model test accuracy from the source report: Vanilla RNN 59.04%, LSTM 83.49%, Bidirectional LSTM 86.98%.
Problems solved and challenges
The image-classification work required fair comparisons across model variants, which meant keeping the training pipeline consistent. The sentiment task required handling variable-length text, noisy review formatting, and the tradeoff between accuracy and training time.
One challenge was resisting the temptation to treat higher accuracy as the whole story. Some experiments improved results but took longer or added complexity. I had to compare training curves, validation accuracy, test accuracy, and runtime so the conclusion was based on behaviour across the experiment, not just the final epoch.
What I learned
- Better accuracy is not the only useful result; training cost and model complexity matter too.
- Regularisation and training settings can change model behaviour as much as architecture changes.
- Sequence models need careful handling of padding and lengths when working with text.
- Error analysis is useful because it shows where a model is confident for the wrong reason.
- Good experiment writeups need to explain the method, the comparison conditions, and the tradeoff behind the result.
Future improvements
- Add a cleaned public notebook with toy-safe examples and no assessment material.
- Rewrite the CNN results into a shorter visual report with fewer charts and clearer takeaways.
- Add confusion matrices or sample misclassifications where they are safe and useful.
- Compare newer transformer-based sentiment models against the recurrent baseline as a follow-up.